Failing to monitor, dying without dignity.
Today, I’m going to tell you about the story of an obscure kernel bug, how we missed it, and how we’re still recovering from the effect
I should preface this by saying that, generally, I like virtual machines.
I have 5 actual servers doing actual things- everything else is a VM in a racked bunch of servers hosted at Telecity in east London.
Generally, these servers are catered for with two uncontested fibre-to-the-rack lines which are layer-4 DDoS scrubbed and redundant power from two seperate generators and dirty feeds. – believe me when I say, no expense is spared on that rack, it’s where 90% of my budget goes and as well it should, given it’s the core business of the company.
I should also preface this by saying ubuntu has held hatred of mine for some time- given we had a development server here in the office and it failed due to a name change of lvm2 to lvm in initramfs causing our server to die irrecoverably and about a days worth of work getting it back in working order (with no documentation on how to do that :)
Anyway, back to our illustrious datacenter!
While at lunch one fateful monday, a rather hurried and out of breath CIO rushes to the bench where I’m eating food: “Sites down”, he stammered.
“Wonderful” I replied, opening up a terminal and going straight for the logging server. – I found that nothing could speak to our database.
After checking the database servers were indeed reachable, and functioning to expected parameters, and having not received any host based alerts, I conclude that “someone changed the code”, however.. I was wrong-
getting back to my desk I check I find that.. the mysql-proxy servers were unreachable, and both ones used happen to be on the same virtual host. Nothing on that virtual host is responding, in fact, neither is the host itself- it hangs in limbo when trying to ssh in.
“Awesome” I think, while logging into the iLO and remembering I don’t have java installed on my machine… No console logs for me!
After hitting the reset switch, I go back to the logging server- we do log kernel events, hopefully we’ll see what happened before it died.
Success.
kernel: [18446743949.922712] BUG: soft lockup - CPU#20 stuck for 17163091968s! [kvm:10666]
kernel: [18446743949.923028] Modules linked in: mptctl mptbase kvm_intel kvm bridge stp bonding fbcon tileblit font bitblit softcursor vga16fb vgastate radeon ttm drm_kms_helper hpilo joydev drm usbhid i2c_algo_bit psmouse bnx2 hid lp serio_raw power_meter parport cciss
kernel: [18446743949.923052] CPU 20:
kernel: [18446743949.923054] Modules linked in: mptctl mptbase kvm_intel kvm bridge stp bonding fbcon tileblit font bitblit softcursor vga16fb vgastate radeon ttm drm_kms_helper hpilo joydev drm usbhid i2c_algo_bit psmouse bnx2 hid lp serio_raw power_meter parport cciss
kernel: [18446743949.923076] Pid: 10666, comm: kvm Not tainted 2.6.32-31-server #61-Ubuntu ProLiant DL360 G7
kernel: [18446743949.923079] RIP: 0010:[] [] vcpu_enter_guest+0x1df/0x4c0 [kvm]
kernel: [18446743949.923101] RSP: 0018:ffff8804cb323d48 EFLAGS: 00000202
kernel: [18446743949.923103] RAX: ffff8804cb323fd8 RBX: ffff8804cb323d68 RCX: ffff880600bb8000
kernel: [18446743949.923106] RDX: 0000000000004402 RSI: 00007fff38846840 RDI: ffff880600bb8000
kernel: [18446743949.923109] RBP: ffffffff81013cae R08: 000000000000002c R09: 0000000000000000
kernel: [18446743949.923111] R10: 0000000000000000 R11: 00007fc5792acdc9 R12: 000000000000002c
kernel: [18446743949.923114] R13: 0000000000001380 R14: 0000000000000001 R15: ffff8804cb323fd8
kernel: [18446743949.923117] FS: 00007f7cd5ce2700(0000) GS:ffff88000c940000(0000) knlGS:ffff880002200000
kernel: [18446743949.923120] CS: 0010 DS: 002b ES: 002b CR0: 0000000080050033
kernel: [18446743949.923123] CR2: 0000000002b9f018 CR3: 000000046fcf8000 CR4: 00000000000026e0
kernel: [18446743949.923126] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
kernel: [18446743949.923128] DR3: 0000000000000000 DR6: 00000000ffff0ff0 DR7: 0000000000000400
kernel: [18446743949.923131] Call Trace:
kernel: [18446743949.923145] [] ? vcpu_enter_guest+0x1ad/0x4c0 [kvm]
kernel: [18446743949.923159] [] ? __vcpu_run+0x7c/0x350 [kvm]
kernel: [18446743949.923173] [] ? kvm_arch_vcpu_ioctl_run+0x8d/0x1d0 [kvm]
kernel: [18446743949.923181] [] ? enqueue_hrtimer+0x82/0xd0
kernel: [18446743949.923191] [] ? kvm_vcpu_ioctl+0x473/0x5c0 [kvm]
kernel: [18446743949.923197] [] ? vfs_ioctl+0x22/0xa0
kernel: [18446743949.923202] [] ? common_timer_set+0x116/0x1a0
kernel: [18446743949.923206] [] ? do_vfs_ioctl+0x81/0x410
kernel: [18446743949.923210] [] ? sys_ioctl+0x81/0xa0
kernel: [18446743949.923216] [] ? system_call_fastpath+0x16/0x1b
Wait..
bender kernel: BUG: soft lockup - CPU#20 stuck for 17163091968s!
Core 20 has been locked up for 500 years?
This has to be an offset error..
After searching for a while I found a relevant Server Fault article. (credit to IRC, somebody else found this article)
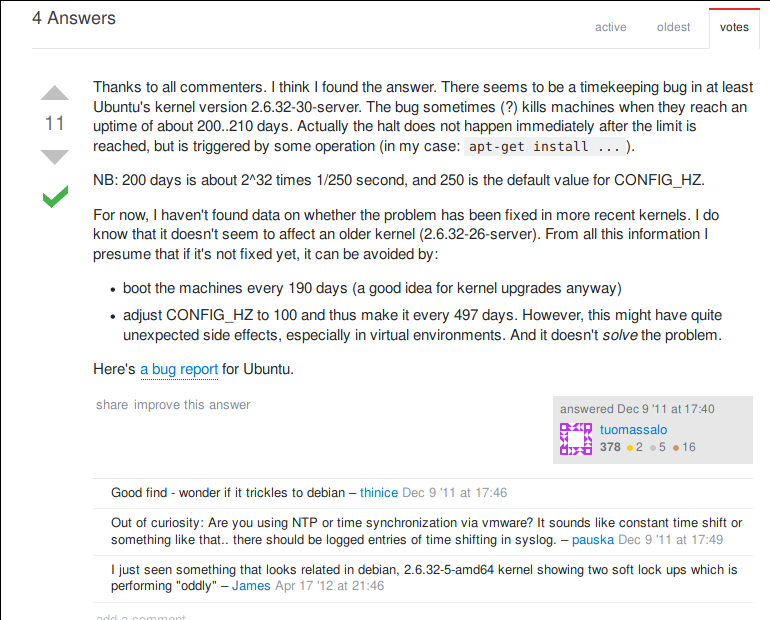
So, if a server is up for more than 200~ days, it will overload the value used for storing the value and cause a kernel panic..
I tend to upgrade my servers in batches in the same week- giving them all a very similar uptime; lets check another machine:
vmhost@max:~$ uptime
17:05:56 up 211 days, 5:18, 1 user, load average: 0.89, 1.00, 1.04
Looks like that’s the culprit, that’s not good. My next question immediately being “Why on earth was I not alerted that a good 10 servers and their host just disappeared”
This question, unfortunately, was disturbingly answered quickly when I read the manifest of the servers running on that host, one of them being our ‘temporary, lets see how it goes’ zabbix server which was also running the web interface, the alert script, and the database.
It’s also the box that didn’t come back.
This was three days ago, I’ve been on a crusade to reboot the servers and hope the patch is actually in updates for ubuntu 10.04.
Side-note: apt-get upgrade seems to love restarting your active database.
so, lessons learned; #
- do not put monitoring on a single box
- do not let your demos become prod
- get some monitoring on your monitoring
Our monitoring system is still offline, but at least now Christmas is over and I can work on making a true system.