Friends don’t let friends use BTRFS for OLTP
I usually write rant-style posts, and today is no exception. A few months ago I was working on a benchmark comparing how PostgreSQL performs on a variety of Linux/BSD filesystems, both traditional ones (EXT3, EXT4, XFS) and new ones (BTRFS, ZFS, F2FS, HAMMER). Sometimes the results came out a bit worse than I hoped for, but most of the time the filesystems behaved quite reasonably and predictably. The one exception is BTRFS …
Now, don’t get me wrong - I’m well aware that filesystem engineering is complex task and takes non-trivial amount of time, especially when the filesystem aims to integrate so much functionality as BTRFS (some would say way too much). Dave Chinner stated that it takes 8-10 years for a filesystem to mature, and I have no reason not to trust his words. I’m not a XFS/EXT4 zealot, I’m actually a huge fan of filesystem improvements (and I don’t really like EXT4 so much) - there’s no reason to think that we can’t do better on new types of storage (SSD, NVRAM) that were not available when the currently mature filesystems like EXT4 or XFS were designed, for example. Or that we can’t provide better filesystem by adding features that were previously available only with additional tools (e.g. snapshotting, which could be done only with LVM before).
But perhaps a certain level of maturity should be reached before claiming a filesystem is “production ready” - it was quite funny hearing such statements a few years back when BTRFS did not even have a fsck tool, it’s much less funny hearing it now when some distributions are either considering using BTRFS as a default filesystem or already did the switch.
I don’t care if Facebook is using BTRFS for parts of their infrastructure, because using BTRFS for carefully selected part of the infrastructure says very little about general maturity. No other filesystem caused me so much frustration and despair during the testing as BTRFS.
Benchmarking trouble … #
The benchmarking is quite simple - create the filesystem, maybe enable some additional tuning options (mkfs and/or mount), kick off the benchmark, let it run for ~4 days, and then pick up the results. This is how it’s supposed to work. With BTRFS, however, things were rather unpredictable
Sometimes the benchmark would simply crash because of “No space left on device” - which is really strange because the largest dataset was just 16GB on a 100GB device. I do understand that COW filesystems do keep multiple copies of the data, so wasting certain amount of space is expected. But this seems a bit ridiculous, I guess.
What’s even more ridicuolous is that when I simply restarted the benchmark from scratch (i.e. by recreating the filesystem etc.), it’d often complete, without the disk space issue!
Which leads me to the other annoying issue - it was not uncommon to see something like this (this particular “top” output is from another machine, which has 16GB of RAM):
Tasks: 215 total, 2 running, 213 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 12.6%sy, 0.0%ni, 87.4%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 16432096k total, 16154512k used, 277584k free, 9712k buffers
Swap: 2047996k total, 22228k used, 2025768k free, 15233824k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
24402 root 20 0 0 0 0 R 99.7 0.0 2:28.09 kworker/u16:2
24051 root 20 0 0 0 0 S 0.3 0.0 0:02.91 kworker/5:0
1 root 20 0 19416 608 508 S 0.0 0.0 0:01.02 init
2 root 20 0 0 0 0 S 0.0 0.0 0:09.10 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:22.72 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
....
and the benchmark would just sit there, doing nothing. On the first few occasions I simply though that something got stuck and proceeded to kill the benchmark. But after the fourth kill I just realized there’s something very CPU intensive happening in BTRFS, which effectively locks the whole filesystem for long periods of time. And sure enough, this is what “perf top” shows:
Samples: 59K of event 'cpu-clock', Event count (approx.): 10269077465
Overhead Shared Object Symbol
37.47% [kernel] [k] btrfs_bitmap_cluster
30.59% [kernel] [k] find_next_zero_bit
26.74% [kernel] [k] find_next_bit
1.59% [kernel] [k] _raw_spin_unlock_irqrestore
0.41% [kernel] [k] rb_next
0.33% [kernel] [k] tick_nohz_idle_exit
0.21% [kernel] [k] run_timer_softirq
And of course, a plethora of “INFO: task kworker blocked for more than 120 seconds.” messages in the system log. I don’t know what exactly is happening (apparently something in metadata maintenance is not quite as efficient as needed), but it clearny does not make the filesystem faster.
… and poor results #
So let’s look at results from runs that actually completed (collected on kernel 4.0). For example with “ssd” and “nobarrier” mount options, read-write performance on large data set looks like this:

Now, that’s what I call jitter! At work I’ve been complaining that while EXT4 performs a bit better than XFS, it’s not as smooth as XFS, but this BTRFS jitter is much much worse. For comparison, let’s look at the EXT4 results again:

Compared to BTRFS, this is utterly smooth. Also EXT4 performs significantly better in terms of throughput as it consistently gives ~5000 tps while BTRFS just about 1200 tps (it’s difficult to see from the chart because of the jitter).
But maybe this is a consequence of COW filesystem? Well, we can check - there’s a F2FS filesystem (not exactly the same feature set as BTRFS, but still a COW filesystem), that behaves like this:
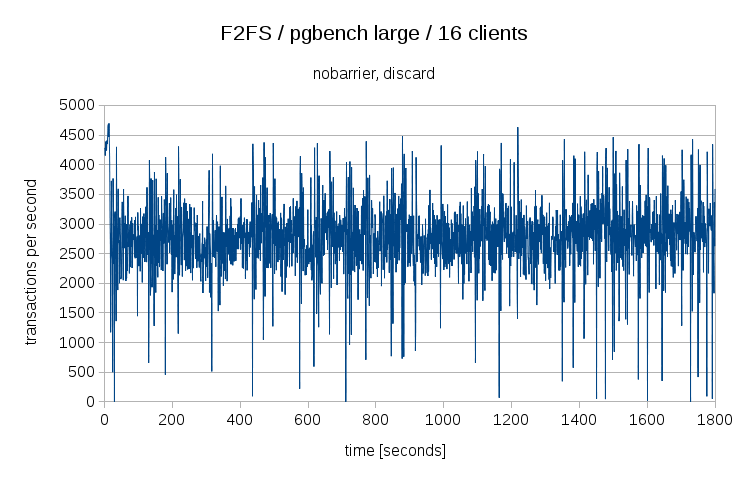
and we also have ZFS on Linux, which behaves like this:
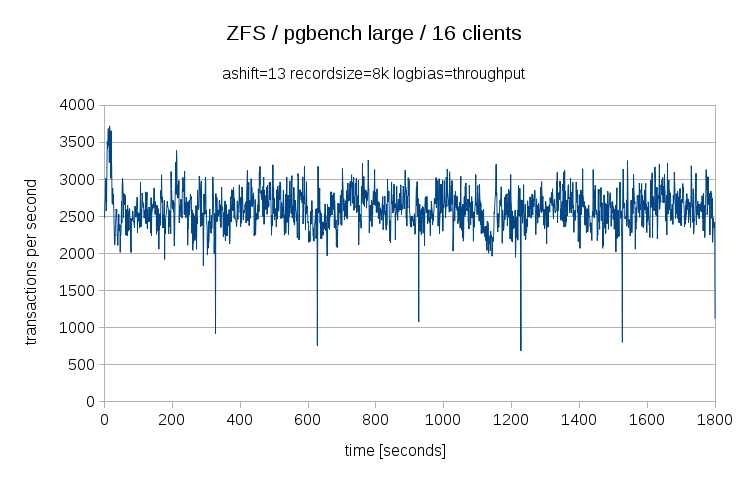
So both of the filesystems perform much better than BTRFS, both in terms of jitter and throughput - both provide ~2500 tps, i.e. about half the performance of EXT4. Which may initially look bad, but if you create the EXT4 on LVM and create a snapshot, you’ll generally see ~50% performance drop exactly because you’ve just turned EXT4 into a COW filesystem. So this is actually pretty good - it’s simply a cost for the features provided by the COW design.
Also, let me point out that ZFS is actually a bit alien in the Linux world - it maintains a separate cache (ARC cache) and has to perform various gymnastics to make it work with the Linux kernel. Yet it performs better than BTRFS!
It’s also not true that this is the worst BTRFS behavior I’ve observed. For example let’s look what happens if you enable discard (TRIM);
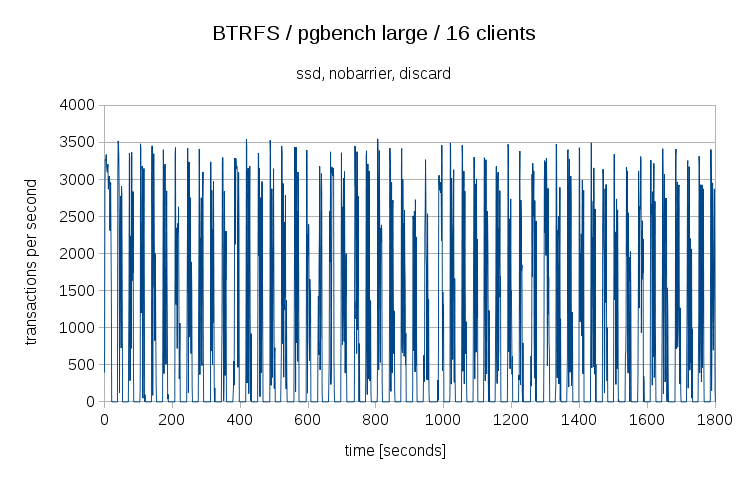
Well, those regular dips (where 0 transactions are processed) are not something you’d like to see on production, that’s for sure …
Graphs: http://imgur.com/a/JLSjC
nodatacow #
Several people asked me in IRC about nodatacow and recommended using this mount option, thus disabling COW on the data (metadata are always copied in BTRFS).
To answer the question, no, I have not used nodatacow for the benchmark runs presented in the post. But I’ve tested nodatacow, and the results look like this:
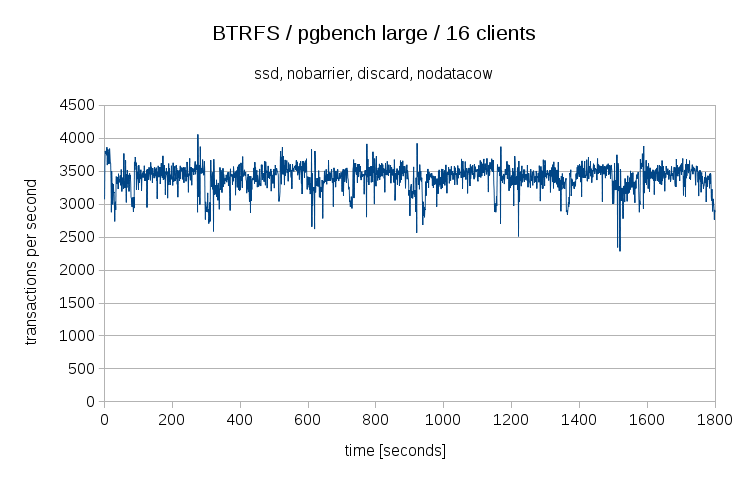
So yes, that helped to improve the performance significantly, both in terms of throughput (3500 tps is actually better than F2FS and ZFS, although it’s still considerably less than EXT4 or XFS) and jitter.
But I think this nodatacow thing is all rather irrelevant - it seems rather strange using a filesystem heavily based on the COW idea, and having to disable the COW to get a decent performance. And not only it seems to contradict the abstract design of the filesystem, it also has practical implications, because by disabling COW on the data, you also make it impossible to use checksums on the data or compression.
You might argue that we do have checksums in PostgreSQL since 9.4 (although only few people is using them in production), and that you would not use compression on an OLTP database anyway. Perhaps, but it clearly is not the case that you can just disable COW on data and keep all the other features, and I would be surprised if it only affected compression and checksums. For example what about btrfs scrub or btrfsck? I’m pretty sure those benefit from the checksums too.
It’s also true that nodatacow does not disable COW completely - when you create a snapshot, the filesystem will perform COW on the data as needed. What happens then? I haven’t tested it, but I’d bet the performance will drop to the state illustrated by the previous chart (~1200 tps, significant jitter). For comparison, with XFS/EXT4, the performance drop is very predictable to almost exactly 50% the performance (which mostly makes sense).
Also, how come that the other two COW filesystems (F2FS and ZFS) perform so much better, even without something like nodatacow? I’m not really familiar with the internals, but clearly there are some design/implementation differences. (I’m aware that F2FS goals are rather different, so the comparison may be a bit unfair - for example F2FS can’t do snapshots, AFAIK).
Conclusion #
I’m not quite sure what exactly my experience with BTRFS proves - I surely did not mean to say that BTRFS in general sucks, but it surely sucks for the OLTP workload that I’ve been testing here.
It might be the case that it performs just fine in other workloads, e.g. read-only workloads, or DWH workloads where most of the access is sequential. Or maybe there’s some secret tuning option that makes is much better even for OLTP workloads?
Any of those would however suggest that BTRFS is not a viable default general-purpose filesystem, because that requires good and stable performance for range variety of workloads by default (i.e. without any extensive tuning).
The results presented here are from kernel 4.0, and maybe those issues were fixed on newer kernels (4.3 was just released). But that’s also suggests BTRFS is not really mature enough, certainly not for serious production deployments. Again, the fact that large companies does not mean it’s a good choice for you.
Or maybe you don’t really care about the performance so much and the other BTRFS features (like snapshotting or subvolumes) are much more interesting for you. In that case I don’t quite understand why you’ve read this post.